LangChainのQuickstartを読む (5) - REST APIとして稼働させる (LangServe)

シリーズ - LangChainのQuickstartを読む
コンテンツ
本シリーズでは、LangChainの Quickstart の内容を元にLangChainの使い方について紹介します。
今回はLangServeを使用して、LangChainのエージェントをREST APIとして提供する方法を見ていきます。
前回までのまとめ
前回は、LangChainに関する回答を行うツールとインターネット検索を行うツールを組み合わせたエージェントを作成しました。
今回このエージェントを使用するため、以下にコードをまとめます。
import os
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.tools.retriever import create_retriever_tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# APIキーを環境変数に設定
with open(".openai") as f:
os.environ["OPENAI_API_KEY"] = f.read().strip()
# Webページのコンテンツをドキュメント化
loader = WebBaseLoader("https://python.langchain.com/docs/get_started/introduction")
docs = loader.load()
# Embeddings読み込み
embeddings = OpenAIEmbeddings()
# ドキュメントを分割
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
# 分割したドキュメントをembeddingsを用いてベクトル化し、ベクトルストアを作成
vector = FAISS.from_documents(documents, embeddings)
# retriever作成
retriever = vector.as_retriever()
# ドキュメント検索を行うツール
retriever_tool = create_retriever_tool(
retriever,
"langchain_search",
"LangChainに関する検索ツール。LangChainに関する質問はこれを使いましょう!",
)
# Tavily用環境変数設定
with open(".tavily") as f:
os.environ["TAVILY_API_KEY"] = f.read().strip()
# インターネット検索を行うツール
search = TavilySearchResults()
# 使用するツールのリスト
tools = [retriever_tool, search]
# テンプレートをLangChain Hubから取得
template = hub.pull("hwchase17/openai-functions-agent")
# エージェントを作成
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, template)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)9. REST APIとして稼働させる (LangServe)
9.1. LangServeをインストール
初めに、以下コマンドでLangServeをインストールします。
pip install "langserve[all]"
9.2. serve.py を作成
serve.pyを以下の内容で作成します。
import os
from typing import List
from fastapi import FastAPI
from langchain import hub
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools.retriever import create_retriever_tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.vectorstores import FAISS
from langchain_core.messages import BaseMessage
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langserve import add_routes
# APIキーを環境変数に設定
with open(".openai") as f:
os.environ["OPENAI_API_KEY"] = f.read().strip()
# Webページのコンテンツをドキュメント化
loader = WebBaseLoader("https://python.langchain.com/docs/get_started/introduction")
docs = loader.load()
# Embeddings読み込み
embeddings = OpenAIEmbeddings()
# ドキュメントを分割
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
# 分割したドキュメントをembeddingsを用いてベクトル化し、ベクトルストアを作成
vector = FAISS.from_documents(documents, embeddings)
# retriever作成
retriever = vector.as_retriever()
# ドキュメント検索を行うツール
retriever_tool = create_retriever_tool(
retriever,
"langchain_search",
"LangChainに関する検索ツール。LangChainに関する質問はこれを使いましょう!",
)
# Tavily用環境変数設定
with open(".tavily") as f:
os.environ["TAVILY_API_KEY"] = f.read().strip()
# インターネット検索を行うツール
search = TavilySearchResults()
# 使用するツールのリスト
tools = [retriever_tool, search]
# テンプレートをLangChain Hubから取得
template = hub.pull("hwchase17/openai-functions-agent")
# エージェントを作成
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
agent = create_openai_functions_agent(llm, tools, template)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# App作成
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# route追加(OpenAI)
add_routes(
app,
llm,
path="/openai",
)
# route追加(エージェント)
# (現在のAgentExecutorはスキーマが定義されていないため、
# 自分でinput/outputスキーマを設定する必要があります。)
class Input(BaseModel):
input: str
chat_history: List[BaseMessage] = Field(
...,
extra={"widget": {"type": "chat", "input": "location"}},
)
class Output(BaseModel):
output: str
add_routes(
app,
agent_executor.with_types(input_type=Input, output_type=Output),
path="/agent",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
9.3. serve.pyを実行
serve.pyを実行します。これにより、REST APIを提供するアプリケーションが起動します。
python serve.py9.4. REST APIを使用する
-
Pythonからは以下のようにして作成したREST APIを使用できます。
from langserve import RemoteRunnable remote_chain = RemoteRunnable("http://localhost:8000/agent/") remote_chain.invoke({ "input": "LangChainとは何でしょうか?", "chat_history": [] })-
実行結果
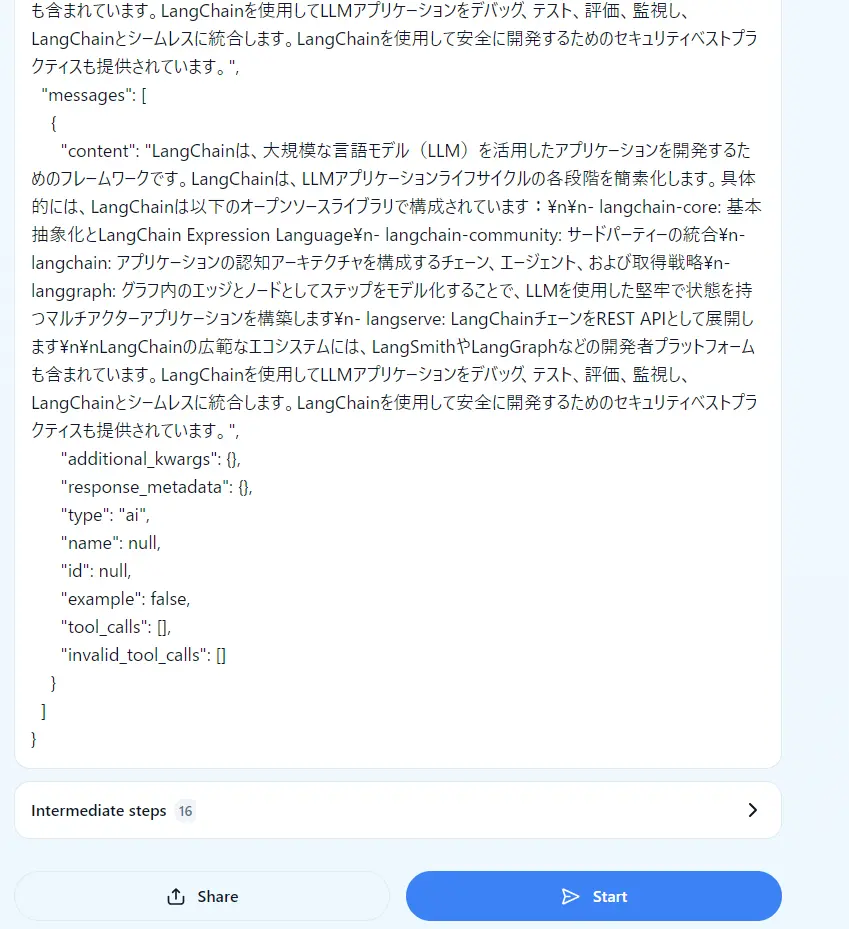
{'output': 'LangChainは、大規模な言語モデル(LLM)によって動作するアプリケーションを開発するためのフレームワークです。LangChainは、LLMアプリケーションライフサイクルの各段階を簡素化します。具体的には、LangChainは以下のオープンソースライブラリで構成されています:\n\n- langchain-core: 基本抽象化とLangChain Expression Language\n- langchain-community: サードパーティーの統合\n- langchain: アプリケーションの認知アーキテクチャを構成するチェーン、エージェント、および取得戦略\n- langgraph: グラフ内のエッジとノードとしてステップをモデル化することで、LLMを使用して堅牢で状態を持つマルチアクターアプリケーションを構築\n- langserve: LangChainチェーンをREST APIとして展開\n\nLangChainの広範なエコシステムには、LangSmithやLangGraphなどの関連ツールも含まれています。LangChainを使用することで、LLMアプリケーションを開発、監視、評価し、信頼性を持って展開することができます。'}
-
-
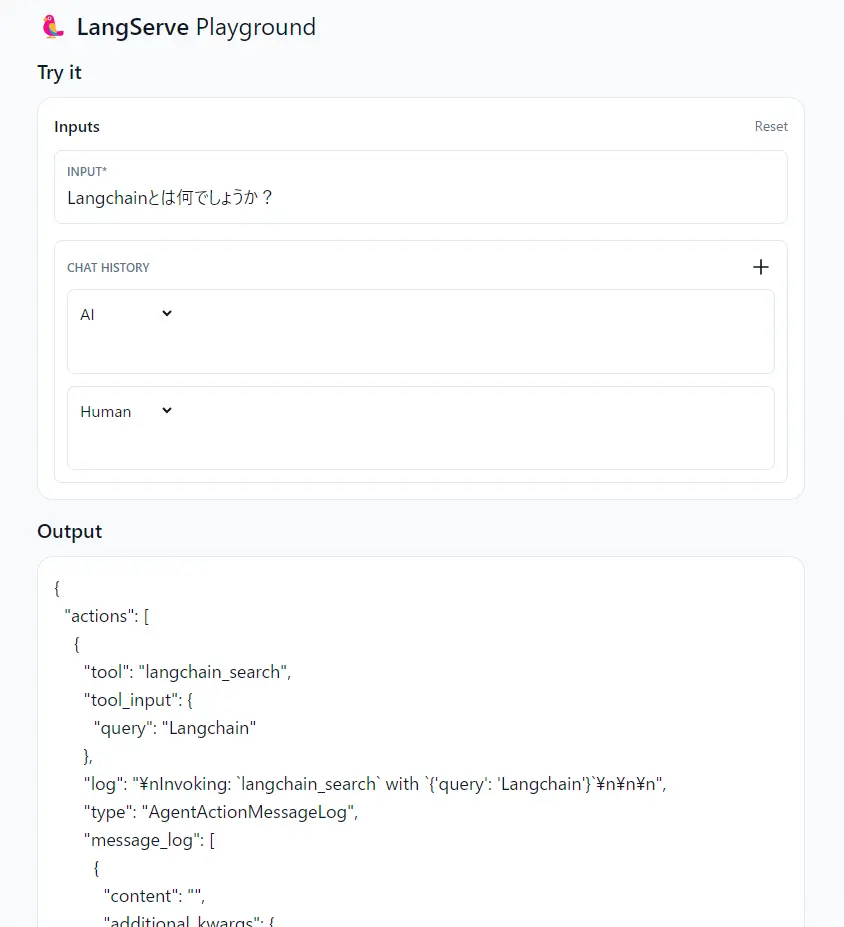
Webブラウザから http://localhost:8000/agent/playground/ にアクセスするとPlaygroundが開きます。
ここからAPIを試すことも出来ます。